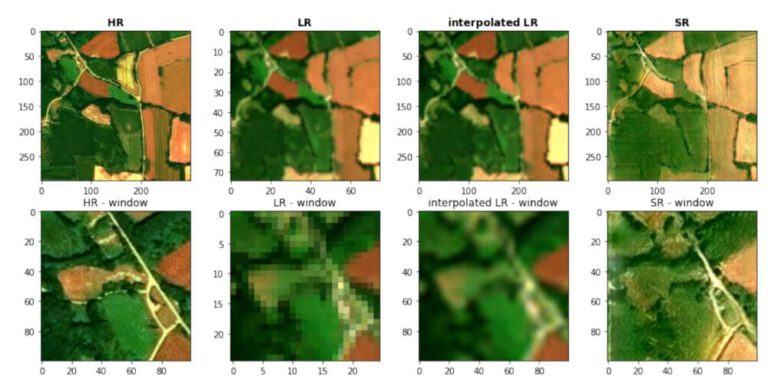



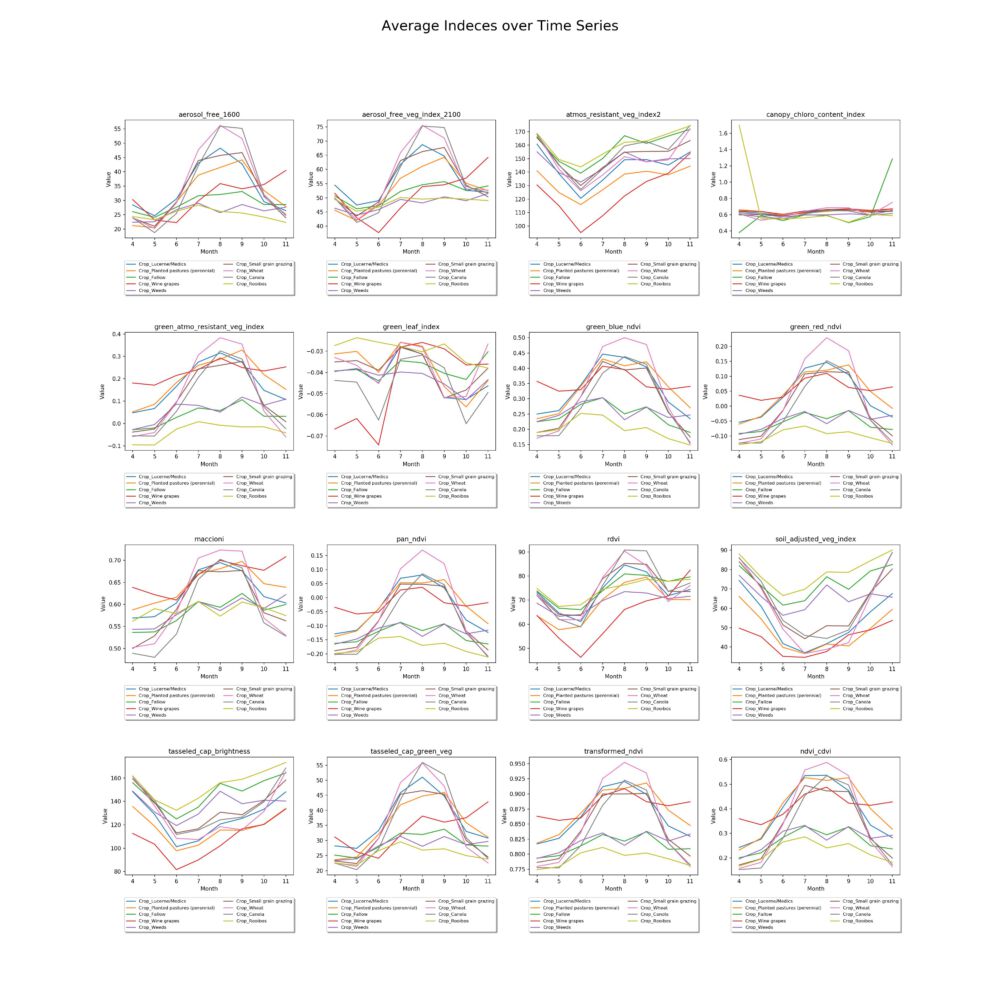
3.5 Prediction
The prediction itself, based on the aforementioned vegetation indices, was performed with a random forest classifier. THe probablities of the classification were extracted with the predict_proba function, that returns a likelihood based on the proportinal results of the individual decision trees in the random forest.
3.5.1 Evaluation
The evaluation metric for this challenge is Cross Entropy with binary outcome for each crop.
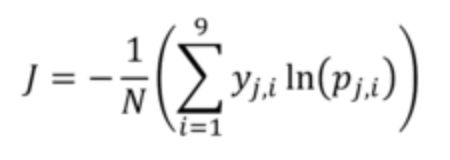
In which:
- j indicates the field number (j=1 to N)
- N indicates total number of fields in the dataset (87,347 in the train and 35,389 in the test)
- i indicates the crop type (i=1 to 9)
- y_j,i is the binary (0, 1) indicator for crop type i in field j (each field has only one correct crop type)
- p_j,i is the predicted probability (between 0 and 1) for crop type i in field j
The final accuracy, as calculated on completely unseen data in the Zindi backend, is 1.2411. That puts my solution in place 41 out of 102 participants.