import dash
import dash_core_components as dcc
import dash_bootstrap_components as dbc
import dash_html_components as html
import pandas as pd
import plotly.graph_objs as go
import plotly.express as px
import geopandas
import numpy as np
from dash.dependencies import Input, Output
import json
from datetime import datetime,timedelta
external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css']
app = dash.Dash(external_stylesheets=[dbc.themes.GRID,dbc.themes.BOOTSTRAP])
app.title = "ICU-Dashboard Austria"
"""
____________________________________________________
"""
"""
LOAD DATA AND PERFORM MUTATIONS
"""
# load ICU data
df = pd.read_csv("/var/www/FlaskApp/FlaskApp/data/ICU_data.csv",sep=",") #full path neces.
# list of states
states = list(df["Bundesland"].unique())
# list of DFs by states
ls_df = []
for i in states:
temp = df[df["Bundesland"]==i]
ls_df.append(temp)
# create list of dicts for droptown menue
options = []
for i in states:
options.append({"label":i,"value":i})
# get data for most recent day & keep only this data
most_recent_date = df['MeldeDatum'].max()
# save df2 (current date dt)
df2 = pd.read_pickle("/var/www/FlaskApp/FlaskApp/data/df2.pkl")
# get day 7 days ago from last data date, convert to string
most_recent_date_datetime = datetime.strptime(most_recent_date,"%Y-%m-%d")
weekago = most_recent_date_datetime + timedelta(days=-7)
weekago_str = weekago.strftime("%Y-%m-%d")
# get icu perc value 7 days ago
icu_7days = df.loc[(df["MeldeDatum"]==weekago_str) & (df["Bundesland"]=="Alle")]["ICU_perc"]
icu_7days = float(icu_7days.to_string(index=False))
# get icu percentage today
icu_today = df.loc[(df["MeldeDatum"]==most_recent_date) & (df["Bundesland"]=="Alle")]["ICU_perc"]
icu_today = float(icu_today.to_string(index=False))
# calculate percentage difference from a week ago to today
icu_dif = round(icu_today-icu_7days,2)
#icu_dif = 2.5
# set color for text according to rising/falling
if icu_dif <=0:
icu_dif_col = "#008000"
else:
icu_dif_col = "#8B0000"
icu_dif = "+"+str(icu_dif)
# load json file containing state geometries
#df_map =geopandas.read_file("/var/www/FlaskApp/FlaskApp/data/austria_adm1.geojson")
# join geometries with most recent data per state
#df_map["Bundesland"] = df_map["NAME_1"]
#df_map = pd.merge(df2,df_map,on="Bundesland")
#df_map = geopandas.GeoDataFrame(df_map, geometry="geometry")
df_map = pd.read_pickle("/var/www/FlaskApp/FlaskApp/data/df_map.pkl")
"""
____________________________________________________
"""
"""
CREATE MAP FIGURE
"""
# make map figure
fig_map = px.choropleth(df_map,geojson=df_map.geometry,color_continuous_scale="reds",range_color=[0,100],
projection="equirectangular",locations=df_map.index,color="ICU_perc",hover_data=["Bundesland","ICU_perc"],width=800, height=600)
fig_map.update_geos(fitbounds="locations",visible=True,
resolution=110,
showcoastlines=True, coastlinecolor="Black",
showland=True, landcolor="LightGray",
showocean=True, oceancolor="LightBlue",
showlakes=False, lakecolor="Blue",
showrivers=False, rivercolor="Blue",
showcountries=False,countrycolor="Black"
)
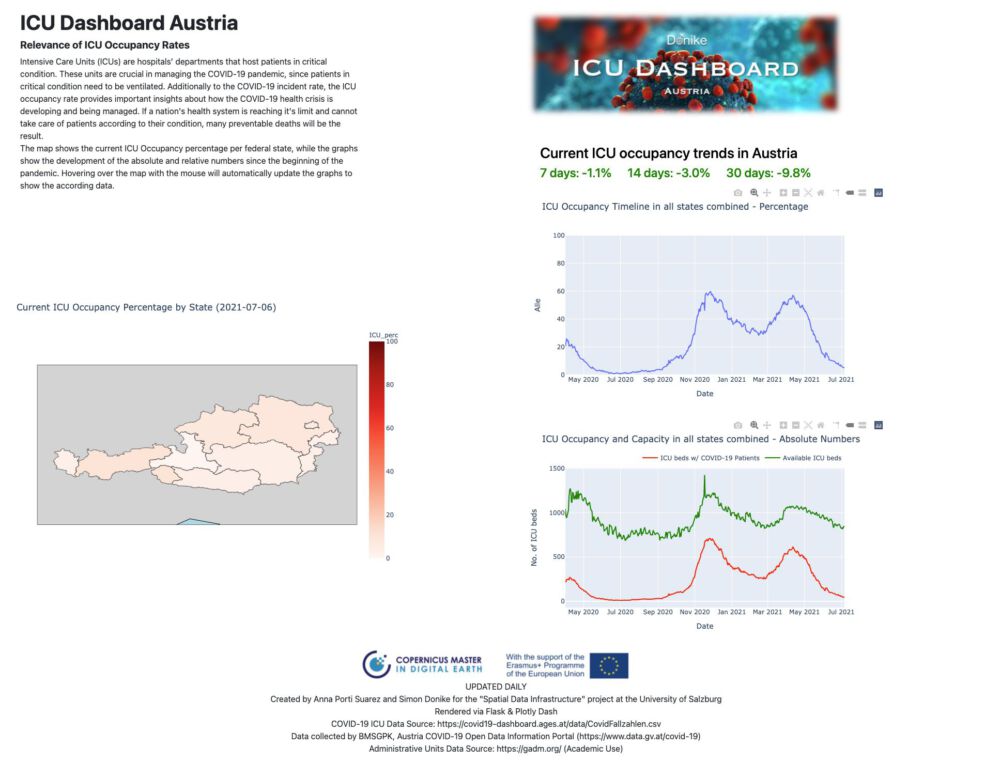
fig_map.update_layout(title_text="Current ICU Occupancy Percentage by State ("+str(most_recent_date)+")")
#fig_map.update_layout(autosize=False)
"""
LOAD DFs FOR UPDATE GRAPHS
"""
df_perc = pd.read_pickle("/var/www/FlaskApp/FlaskApp/data/df_perc.pkl")
df_FZICU = pd.read_pickle("/var/www/FlaskApp/FlaskApp/data/df_FZICU.pkl")
df_ICU_cap = pd.read_pickle("/var/www/FlaskApp/FlaskApp/data/df_ICU_cap.pkl")
"""
CREATE GRAPH OBJECTS
"""
fig_graph = go.Figure()
fig_graph = px.line(df_perc, x="MeldeDatum",y="Alle",title="ICU Occupancy Timeline in all states combined - Percentage",
labels={"MeldeDatum": "Date"})
fig_graph.update_yaxes(range=[0,100])
fig_graph_FZICU = go.Figure()
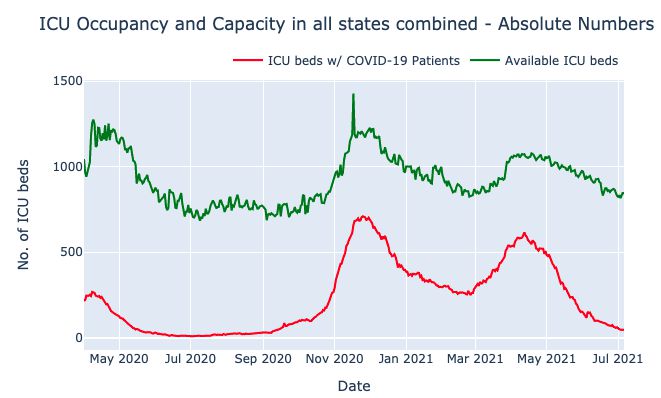
fig_graph_FZICU.add_trace(go.Scatter(x=df_FZICU["MeldeDatum"],y=df_FZICU["Alle"],name="ICU beds w/ COVID-19 Patients",
mode="lines",line=go.scatter.Line(color="red"),showlegend=True))
fig_graph_FZICU.add_trace(go.Scatter(x=df_ICU_cap["MeldeDatum"],y=df_ICU_cap["Alle"],name="Available ICU beds",
mode="lines",line=go.scatter.Line(color="green"),showlegend=True))
fig_graph_FZICU.update_layout(title_text="ICU Occupancy and Capacity in all states combined - Absolute Numbers",
xaxis_title="Date",
yaxis_title="No. of ICU beds",)
fig_graph_FZICU.update_layout( legend=dict(
orientation="h",
yanchor="bottom",
y=1.02,
xanchor="right",
x=1,
))
"""
CREATE PIE CHART DATA AND FIG
"""
#df_pie = df.loc[df['MeldeDatum'] == most_recent_date]
#df_pie = df_pie[df_pie.Bundesland == 'Alle']
#fig_pie = px.pie(df_pie, values='FZICU', names='FZICUFree')
#fig_pie = px.pie()
"""
____________________________________________________
"""
"""
APP LAYOUT
"""
styles = {
'pre': {
'border': 'thin lightgrey solid',
'overflowX': 'scroll'
}
}
Col1 = dbc.Col([
dbc.Row([html.H1("ICU Dashboard Austria",style={'font-weight': 'bold'})]),
dbc.Row([
html.H5("Relevance of ICU Occupancy Rates",style={'font-weight': 'bold'}),
html.Div("Intensive Care Units (ICUs) are hospitals’ departments that host patients in critical condition. These units are crucial in managing the COVID-19 pandemic, since patients in critical condition need to be ventilated. Additionally to the COVID-19 incident rate, the ICU occupancy rate provides important insights about how the COVID-19 health crisis is developing and being managed. If a nation's health system is reaching it's limit and cannot take care of patients according to their condition, many preventable deaths will be the result.",style={'width': '70%'}),
html.Div("The map shows the current ICU Occupancy percentage per federal state, while the graphs show the development of the absolute and relative numbers since the beginning of the pandemic. Hovering over the map with the mouse will automatically update the graphs to show the according data.", style={'width': '70%'}),
]),
dbc.Row([
html.Div([
dcc.Graph(id="map1", figure=fig_map,style={"vertical-align":"middle",'margin-top':'25%'}),
], style={"text-align":"center",'margin-left':'-5%'}),
]),
])
Col2 = dbc.Col([
#image ICU DASHBOARD
dbc.Row([
html.Div([
html.A([
html.Img(src="https://www.donike.net/wp-content/uploads/corona_Dashboard_Cover_2.jpg",style={'height':'100%', 'width':'100%'} )
], href='https://www.donike.net'),
],style={'margin-left':'1%','padding-bottom':'8%'})
]),
dbc.Row([
html.H4('7-day ICU Occupancy trend in Austria: '+str(icu_dif)+'%', style={'color': icu_dif_col,"text-align":"center",'margin-left':'5%'}),
]),
dbc.Row([
html.Div([
dcc.Graph(id="graph_icu",figure=fig_graph,style={'width': '100%'}),
dcc.Graph(id="graph_FZICU",figure=fig_graph_FZICU,style={'width': '100%'}),
]),
]),
])
app.layout = html.Div([
dbc.Row([
dbc.Col(Col1, width=6,style={'margin-left' : '2%'}),
dbc.Col(Col2, width=4),
]),
dbc.Row([
# Footer
html.Div([
html.Img(src="https://www.donike.net/wp-content/uploads/copernicus_eu_logos_combined.jpg", style={'width':'60%','textAlign':'center'}),
html.P(['UPDATED DAILY',
html.Br(),'Created by Anna Porti Suarez and Simon Donike for the "Spatial Data Infrastructure" project at the University of Salzburg',
html.Br(),'Rendered via Flask & Plotly Dash',
html.Br(),"COVID-19 ICU Data Source: https://covid19-dashboard.ages.at/data/CovidFallzahlen.csv",
html.Br(),"Data collected by BMSGPK, Austria COVID-19 Open Data Information Portal (https://www.data.gv.at/covid-19)",
html.Br(),'Administrative Units Data Source: https://gadm.org/ (Academic Use)'],
style={'textAlign': 'center'})
],style={'textAlign': 'center'})
], justify="center")
],style={'margin-top' : '1%'}
)
# close app layout div
"""
____________________________________________________
"""
""" # Callback for PERC graph
@app.callback(
Output(component_id='graph_icu', component_property='figure'),
Input(component_id='dropdown',component_property="value") #, component_property='value')
)
def update_output_div(input_value):
if input_value == "Alle":
name = "all states combined"
else:
name=input_value
fig_graph = px.line(df_perc, x="MeldeDatum",y=input_value,title="ICU Occupancy Timeline in "+name+" - Percentage",
labels={"MeldeDatum": "Date"})
fig_graph.update_yaxes(range=[0,100])
#fig.graph.update_layout(xaxis_title="Date",yaxis_title="ICU Occupancy Percentage")
return fig_graph """
""" # Callback for absolute numbers graph
@app.callback(
Output(component_id='graph_FZICU', component_property='figure'),
Input(component_id='dropdown',component_property="value") #, component_property='value')
)
def update_output_div(input_value):
if input_value == "Alle":
name = "all states combined"
else:
name=input_value
#fig_graph_FZICU = px.line(df_FZICU, x="MeldeDatum",y=input_value,title="ICU Occupancy and Capacity in "+name+" - Absolute Numbers")
fig_graph_FZICU = go.Figure()
fig_graph_FZICU.add_trace(go.Scatter(x=df_FZICU["MeldeDatum"],y=df_FZICU[input_value],name="ICU beds w/ COVID-19 Patients",
mode="lines",line=go.scatter.Line(color="red"),showlegend=True))
fig_graph_FZICU.add_trace(go.Scatter(x=df_ICU_cap["MeldeDatum"],y=df_ICU_cap[input_value],name="Available ICU beds",
mode="lines",line=go.scatter.Line(color="green"),showlegend=True))
fig_graph_FZICU.update_layout(title_text="ICU Occupancy and Capacity in "+name+" - Absolute Numbers",
xaxis_title="Date",
yaxis_title="No. of ICU beds",)
fig_graph_FZICU.update_layout(legend=dict(
orientation="h",
yanchor="bottom",
y=1.02,
xanchor="right",
x=1
))
return fig_graph_FZICU """
# Callback for PERC graph Test
@app.callback(
Output(component_id='graph_icu', component_property='figure'),
Input('map1', 'hoverData'))
def display_hover_data(hoverData):
x = json.dumps(hoverData, indent=2, ensure_ascii=False)
y = x.split('"customdata": [')[1].strip().split('",')[0].strip('"')
name = "all states combined"
input_value = "Alle"
if hoverData:
name=y
input_value = y
fig_graph = px.line(df_perc, x="MeldeDatum",y=input_value,title="ICU Occupancy Timeline in "+name+" - Percentage",
labels={"MeldeDatum": "Date"})
fig_graph.update_yaxes(range=[0,100])
#fig.graph.update_layout(xaxis_title="Date",yaxis_title="ICU Occupancy Percentage")
return fig_graph
# Callback for absolute numbers graph
@app.callback(
Output(component_id='graph_FZICU', component_property='figure'),
Input('map1', 'hoverData'))
def update_output_div(hoverData):
x = json.dumps(hoverData, indent=2, ensure_ascii=False)
y = x.split('"customdata": [')[1].strip().split('",')[0].strip('"')
#default_value == "Alle"
name = "all states combined"
input_value = "Alle"
if hoverData:
name=y
input_value = y
#fig_graph_FZICU = px.line(df_FZICU, x="MeldeDatum",y=input_value,title="ICU Occupancy and Capacity in "+name+" - Absolute Numbers")
fig_graph_FZICU = go.Figure()
fig_graph_FZICU.add_trace(go.Scatter(x=df_FZICU["MeldeDatum"],y=df_FZICU[input_value],name="ICU beds w/ COVID-19 Patients",
mode="lines",line=go.scatter.Line(color="red"),showlegend=True))
fig_graph_FZICU.add_trace(go.Scatter(x=df_ICU_cap["MeldeDatum"],y=df_ICU_cap[input_value],name="Available ICU beds",
mode="lines",line=go.scatter.Line(color="green"),showlegend=True))
fig_graph_FZICU.update_layout(title_text="ICU Occupancy and Capacity in "+name+" - Absolute Numbers",
xaxis_title="Date",
yaxis_title="No. of ICU beds",)
fig_graph_FZICU.update_layout(
legend=dict(
orientation="h",
yanchor="bottom",
y=1.02,
xanchor="right",
x=1
))
return fig_graph_FZICU
"""
# Callback for Pie Chart from Map Hover
@app.callback(
Output(component_id='fig_pie', component_property='figure'),
Input(component_id='fig_map',component_property="hover")
)
def update_pie(input_value):
if input_value is None:
fig_pie = go.Figure(data=[go.Pie(labels=labels, values=values)])
return fig_pie
"""
"""
____________________________________________________
"""
"""
SERVER SETTINGS
"""
# added this
server = app.server
if __name__ == '__main__':
app.run_server(debug=True)