
All steps performed in the diagram above are retraced and investigated.
Model Builder Workflow
1. Fill
Firstly, the DEM is altered using the Fill tool in order to eliminate sinks. A sink is identified by its depth, which is the main parameter we change within the fill tool. Sinks which are under the threshold depth are filled within the DEM, which eliminates the hypothetical creation of small “lakes” in our study area, which are most likely due to DEM inaccuracies because of the resolution.
2. Flow Direction
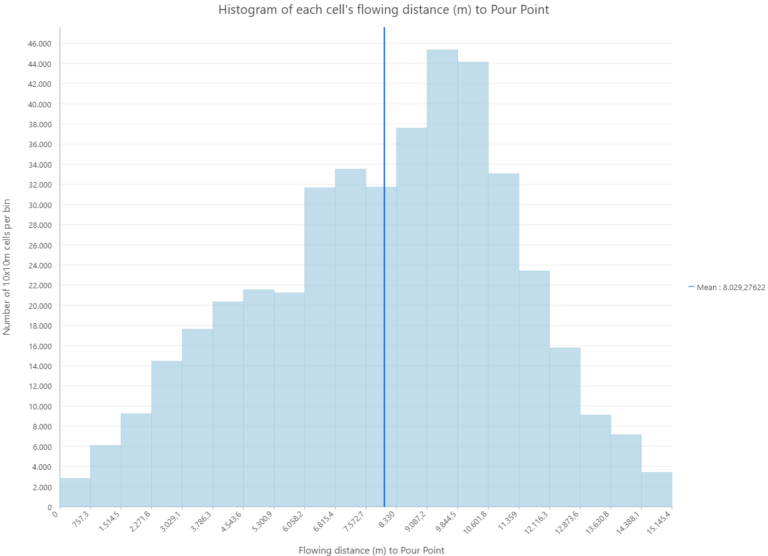
Next up, the flow direction is calculated. For each cell in a raster, the closest cell with the lowest value is chosen as the flow direction. The D8 algorithm, which is named this way because the direction of flow can go to any of the 8 cell neighbors, choses the steepest decline in elevation for each cell, also taking the distance to the cells into account. A diagonal cell for example of course is aprox. 1.4 times further than a direct neighbor. Each cell is then encoded with the direction of flow, see figure number 3.


3. Watershed (and import of pour point)
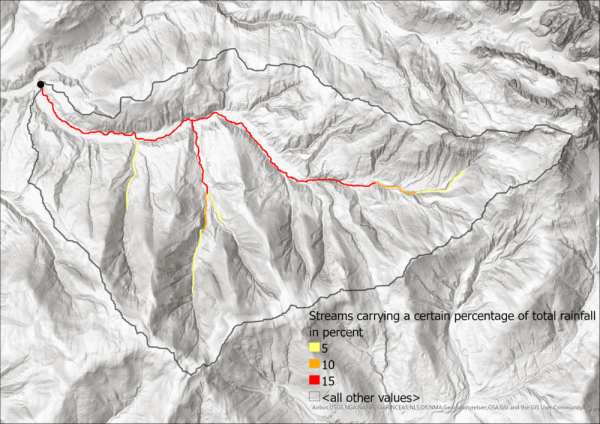
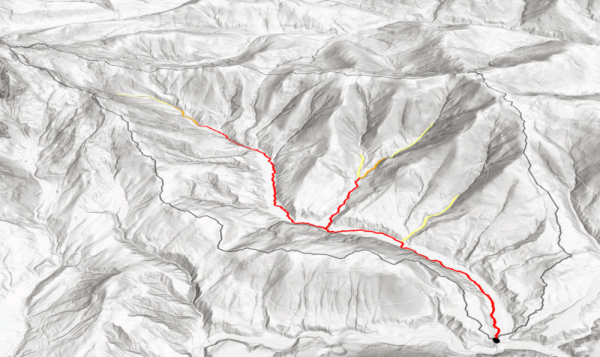
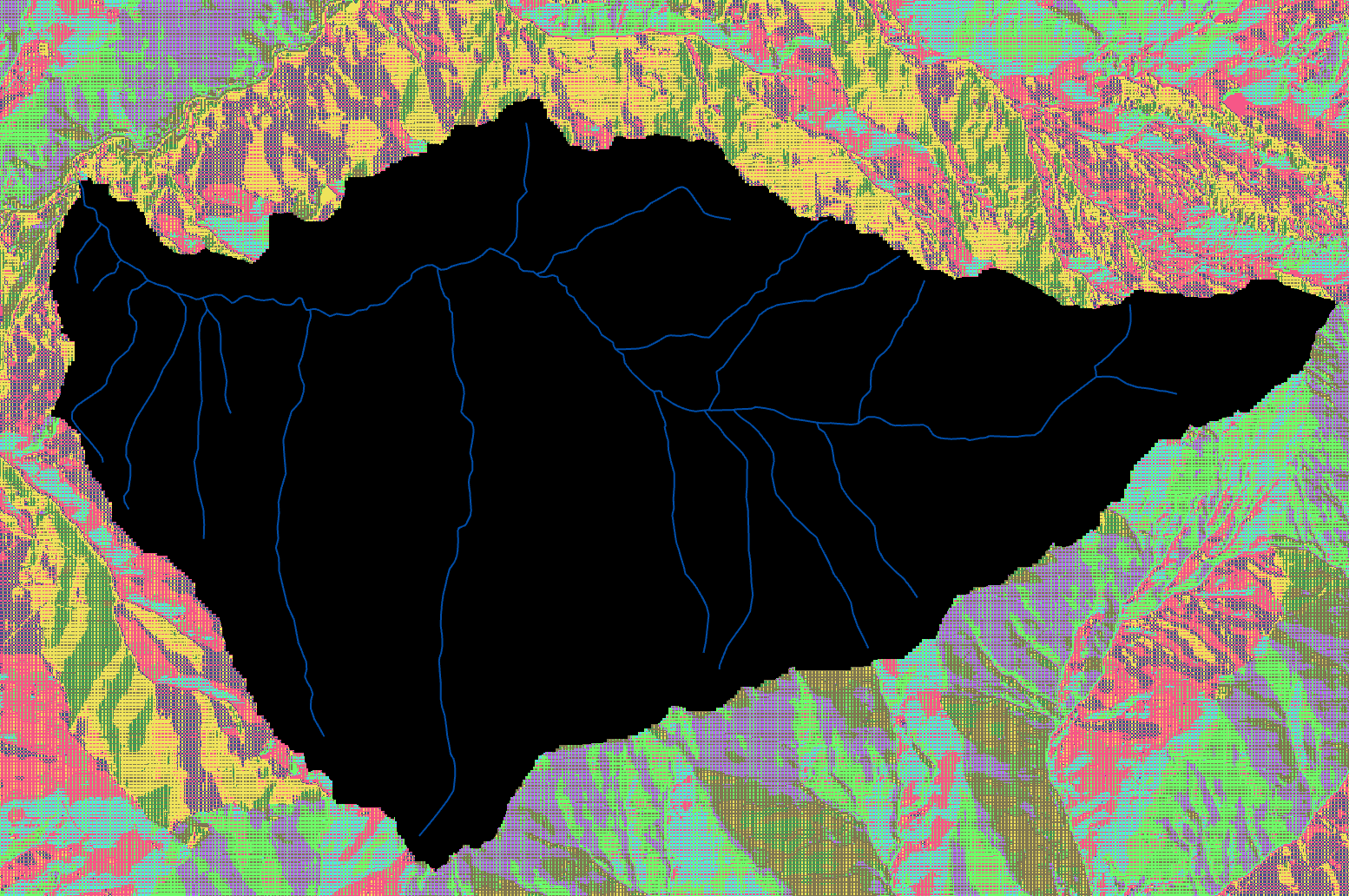
After calculating the flow direction, we delineate watershed areas. In order to create the watershed, we need to identify the lowest point and therefore pouring point of the Neubach, which is of course located where the Neubach drains into the Salzach. Please note that in this ArcGIS Model, it is assumed that the pour point is already known. If that is not the case, the flow accumulation needs to be executed first and the lowest point of the watershed area identified, before the watershed can be created. Image 5 shows the selection of the pour point. For the sake of clarity, this model assumes that the point is known already so that the area can be masked before the other outputs are created. Also, the results will need to be clipped later anyway in order to produce clean Histograms and other analysis, so it is more efficient to mask the input raster on which the following steps are based on than to mask the multiple results later on.

This model imports a .csv file which contains the coordinates of the manually selected pour point. The watershed function in ArcGIS Pro did not accept a manually drawn point as input, so the workaround with the csv creation had to be taken.
Manually defining the exact pixel which will serve as the pour point also eliminates the need for the “Snap Pour Point” tool. This tool would move the pour point to the highest accummulated flow cell within a certain distance, but is not used in this case because we are certain to have chosen the right spot and do not want the tool to move the point towards the Salzach river, which would completely ruin the workflow.
The watershed tool returns a raster which contains all pixels that drain into the pour point, based on the D8 flow direction raster and the given pour point. By tracing the flow directions, the tool “crawl up” from each cell. When the tool can not climb higher in any direction because the terrain is falling again, it stops and returns the watershed area.
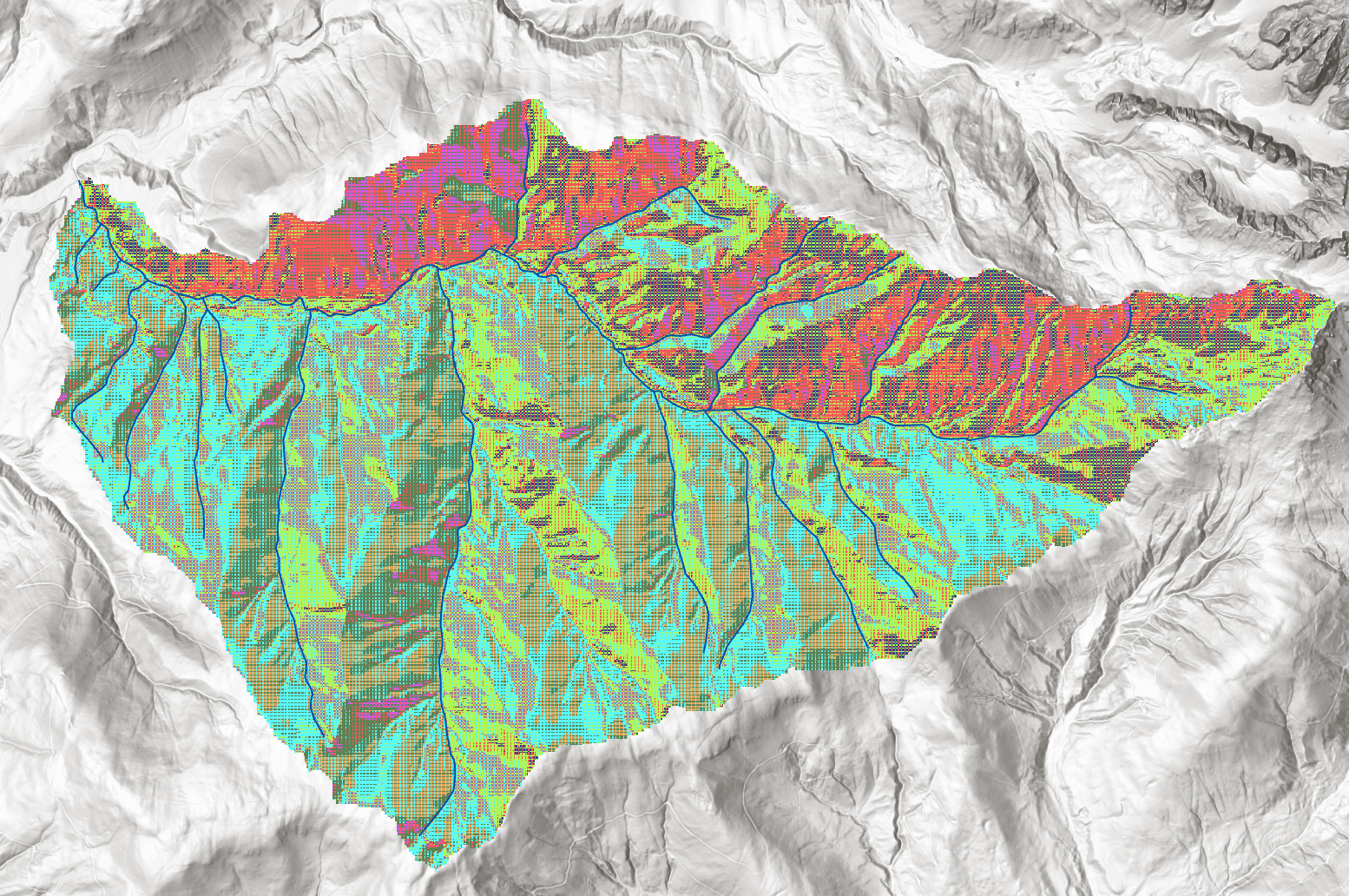
4. Converting the watershed raster to a polygon and masking the flow direction to the watershed
Since now the watershed area is known, this layer is vectoriued in order to save the limits of the dataset. Also, because the following steps will be based on the flow direction raster, it is masked by the extent of the watershed and saved in order to speed up processing and clear up the visualization.
5. Flow accumulation
The flow accumulation was already introduced earlier in the extract on how to find the pouring point of a given area, but now the model performs the flow accumulation analysis automatically based on the masked flow direction layer. The flow direction analyses each cell and moves “upward” based on the flow direction layer, counting how many cells drain into the cell in question. Therefore, each cell contains the number of how many cells drain into it. This layer is a bit hard to visualize because most cells only have a handfull of “upward” cells, but the number grows quickly the further down the catchment area we go. The median number of cells which drain into each cell is 2. Since all cells of the watershed drain into the pour point, the pour point has a flow accumulation value of the total amount of cells in the raster (minus one, itself).